强化学习在微调语言模型时,相比传统的监督学习有哪些优势,为什么它能够在有限标注数据情况下仍然提升模型性能?
参考资料
参考资料


Moonshot回答
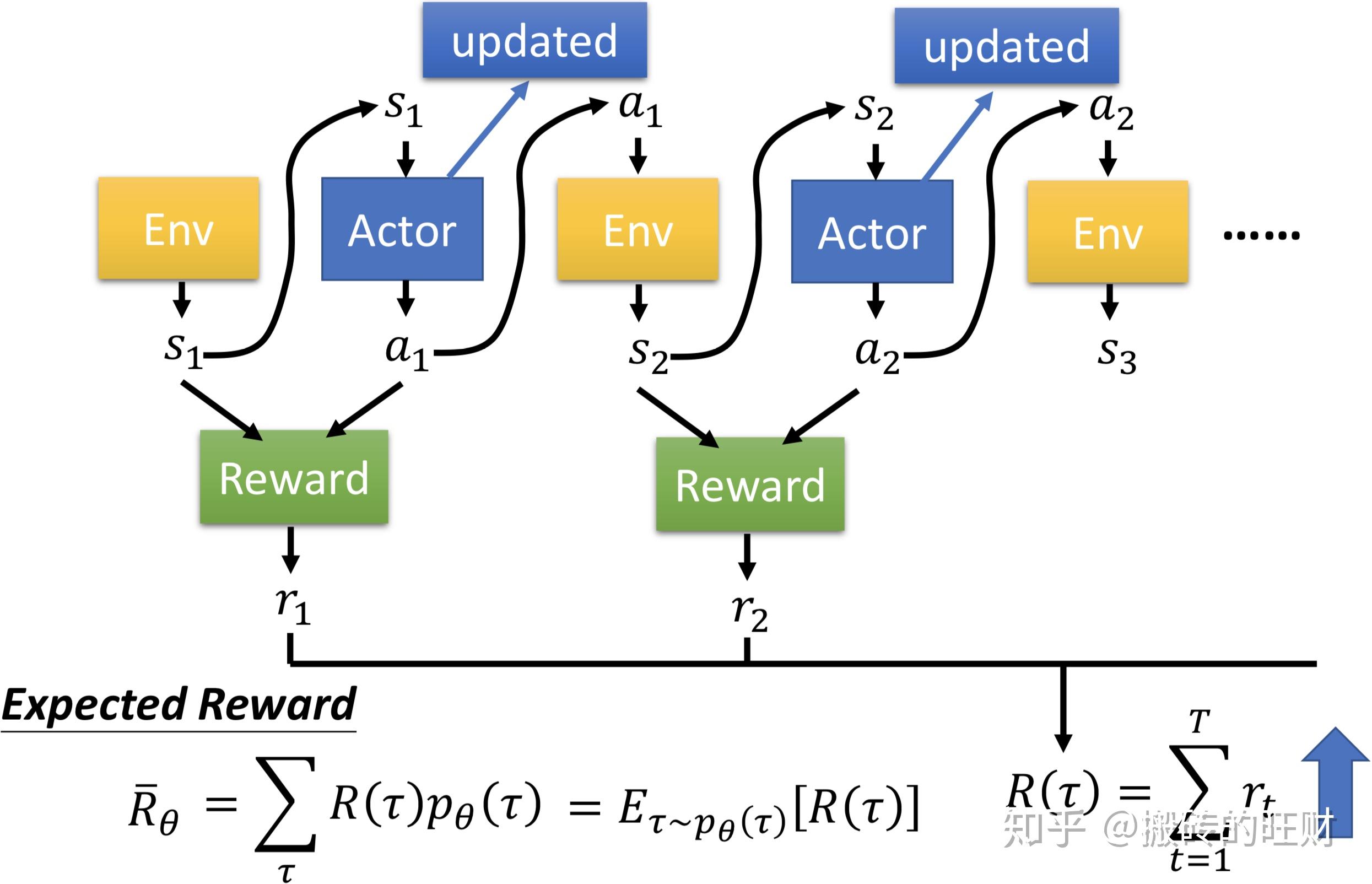
强化学习在微调语言模型时相比传统监督学习具有以下优势:
-
更少的标注数据需求:强化学习通过奖励模型引导模型学习,可以在有限的标注数据下进行有效的学习,而传统监督学习通常需要大量标注数据。
-
动态调整学习策略:强化学习能够根据环境反馈动态调整学习策略,而传统监督学习通常采用固定的学习策略。
-
提高模型的泛化能力:强化学习通过与环境的交互学习,能够提高模型在不同任务和领域的泛化能力。
-
优化模型行为:强化学习通过奖励机制优化模型行为,使其更符合人类的偏好和价值观。
-
提升模型性能:强化学习通过不断试错和学习,能够持续提升模型性能。
强化学习之所以能在有限标注数据情况下提升模型性能,是因为它利用了以下机制:
- 奖励建模:通过奖励模型评估模型输出,引导模型学习。
- 策略优化:通过强化学习算法(如PPO)不断优化模型策略。
- 数据增强:在数据稀缺的情况下,通过生成合成训练数据来扩充数据集。
- 主动学习:选择对模型提升最有帮助的样本进行标注和学习。
综上所述,强化学习通过这些机制和优势,能够在有限标注数据的情况下提升语言模型的性能。
继续提问
相关问题
牛津大学是如何成为英语国家中最古老的大学的?
邢侯为何在商纣王时期被杀?
δ-变形菌在生态系统中的具体作用是什么,它们如何参与硫循环和其他重要生物地球化学过程?
巴巴罗萨行动如何为纳粹对犹太人的大规模屠杀铺平了道路?
希尔佩里克二世在与查理·马特的对抗中经历了哪些关键战役?
咸阳至郦邑距离不远,秦王为何能在一天之内追回李斯并恢复其官职?
是什麽因素导致了一些地方的外来企业家启动资金远高于当地企业家的现象?
2012年至2018年间,哪些国家的新闻事件被多家国际媒体同时报道?
奥斯曼帝国在1453年攻陷君士坦丁堡后,对欧洲的文化和科学产生了什么影响?
请对比TOTO 智能马桶(标准款/300坑距)和海尔(V-158Plus)的参数,并分析它们的优缺点,然后打分推荐